Spectro Team · May 5, 2026 · 8 min read
The Science Behind Fake Lossless Audio Detection
How does a tool know a FLAC file contains a 128 kbps MP3? The answer is in the frequency spectrum. A breakdown of the peer-reviewed research behind spectral fake lossless detection.
Quick Answer: Lossy MP3 encoders discard audio data above a frequency threshold that varies by bitrate — 16 kHz at 128 kbps, up to 20 kHz at 320 kbps. This cutoff is permanent and survives re-encoding into any lossless container. A Support Vector Machine trained on the 16–20 kHz power spectral density of 2,512 songs detects the original bitrate with 97% accuracy and transcoding with 99% accuracy (D'Alessandro & Shi, ACM MM&Sec 2009).
Why lossy encoding leaves a permanent fingerprint
When an MP3 encoder compresses audio, it applies psychoacoustic models to decide which information to discard. One of the most consistent strategies is high-frequency attenuation: audio content above a certain threshold is removed because human hearing is least sensitive in that range.
The threshold varies by bitrate:
| Bitrate | Frequency cutoff |
|---|---|
| 128 kbps | ~16 kHz |
| 192 kbps | ~17.5 kHz |
| 256 kbps | ~18.5–19 kHz |
| 320 kbps | ~20 kHz |
Once that content is discarded, it cannot be recovered. Re-encoding to a higher bitrate — or wrapping the decoded audio in a FLAC or WAV container — simply re-encodes the silence above the cutoff. The fingerprint remains exactly where the original encoder left it.
This irreversibility is the foundation of all spectral fake lossless detection.
How frequency spectrum analysis detects the original bitrate
In 2009, researchers Brian D'Alessandro and Yun Q. Shi at the New Jersey Institute of Technology published the foundational study on automatic bitrate detection from frequency spectrum data (MP3 Bit Rate Quality Detection through Frequency Spectrum Analysis, ACM Multimedia and Security Workshop, Princeton).
Their method works as follows:
- Decompress the file to PCM audio (WAV format at 1411 kbps — CD quality)
- Compute the Power Spectral Density (PSD) of the full audio signal
- Extract only the 16–20 kHz range, divided into 100 frequency bands of ~43 Hz each
- Use those 100 values as features for a Support Vector Machine (SVM) classifier
The dataset: 2,512 songs from 94 artists — Metallica, Radiohead, Nirvana, U2, Sarah McLachlan — covering fast rock and slow acoustic music to verify that the method generalizes across genres. Each song was encoded at five bitrates: 128, 192, 256, 320 kbps CBR and VBR-0 (highest VBR level, averaging 224–300 kbps).
Results:
- 97% average accuracy across all bitrate classes on a test set of 2,012 songs
- 99% accuracy detecting transcoded audio: 128 kbps MP3s re-encoded to 320 kbps were correctly identified as 128 kbps sources in 99.3% of cases
The key insight from the paper: "the spectral properties of the transcoded signal does not change much from the original bit rate." A PSD plot of a 128 kbps MP3 transcoded to 320 kbps is nearly indistinguishable from the original 128 kbps file. The re-encoding adds no information — it simply allocates more bits to encode the cutoff more precisely.
The one genuinely ambiguous case
The only class with meaningfully lower accuracy was 256 kbps CBR: 92.4% correct, versus 97–99% for every other class.
The reason is a genuine data overlap. VBR-0 — the highest variable bitrate mode — produces average bitrates of 224–300 kbps, which overlaps with 256 kbps CBR. Since VBR adjusts temporally, some song segments encode at rates indistinguishable from 256 CBR and vice versa. 6.3% of 256 kbps CBR files were misclassified as VBR-0; 4.8% of VBR-0 files were misclassified as 256 kbps.
This is not a flaw in the method — it reflects a genuine ambiguity in the source material. In practice, this is the only zone where a verdict of MEDIUM (rather than LOSSLESS or FAKE) is the honest response.
Beyond MP3: detecting upsampling and upscaling in hi-res files
The problem extends beyond MP3 transcoding. A 24-bit/96 kHz FLAC file can be fake lossless in two additional ways: the audio may have been recorded at 16 bits and upscaled (bit-depth inflated), or recorded at 44.1 kHz and upsampled (sample rate inflated).
Lacroix et al. addressed both in Lossless Audio Checker: A Software for the Detection of Upscaling, Upsampling, and Transcoding in Lossless Musical Tracks (AES 139th Convention, 2015), validated on 892 files with known ground truth.
Upscaling detection (100% accuracy): A genuine 24-bit recording uses the full quantization range of a 24-bit integer (±8,388,607). An upscaled 16-bit recording — one that was simply zero-padded to 24 bits — uses only the range of a 16-bit integer (±32,767). Checking whether any sample exceeds the 16-bit ceiling requires no frequency analysis at all: it is a purely temporal domain check.
Upsampling detection (91.3% accuracy): A genuine 96 kHz recording has real audio content extending toward its Nyquist frequency (48 kHz). An upsampled 44.1 kHz recording has content only up to 22.05 kHz — the Nyquist of the original. The band between 22.05 and 48 kHz contains only the residual energy of the upsampling filter's interpolation. Lacroix et al. compare the Power Spectral Density of that extended band against the theoretical quantization noise floor for the declared bit depth. If the extended band's energy does not exceed that floor, the content is not real — it is upsampled.
AAC transcoding detection (100% accuracy): A dedicated filterbank-based method, testing 8,192 parameter combinations per file. Computationally expensive (~2 minutes per file on 2015 hardware), but achieves 100% accuracy at any AAC bitrate.
The AES 2015 paper confirms that spectral analysis of the extended frequency band is the standard forensic approach for detecting fake hi-res lossless files.
The state of the art: transformer-based temporal localization
The most recent advance in this field moves beyond file-level classification to frame-level detection. Xiang et al. (Purdue University / Politecnico di Milano, IEEE 2022) trained transformer networks on 486,743 MP3 audio clips to detect not just whether a file has been multiply compressed, but where in the timeline the compression occurred — identifying spliced or partially edited audio at the MP3 frame level.
This represents a different forensic use case (audio authenticity for legal or media applications) rather than the batch library scanning that Spectro targets. But it illustrates the maturity of the field: the core principle — that lossy compression leaves measurable spectral traces that survive re-encoding — has been validated across multiple research groups, encoders, and methodological approaches spanning 15 years of peer-reviewed work.
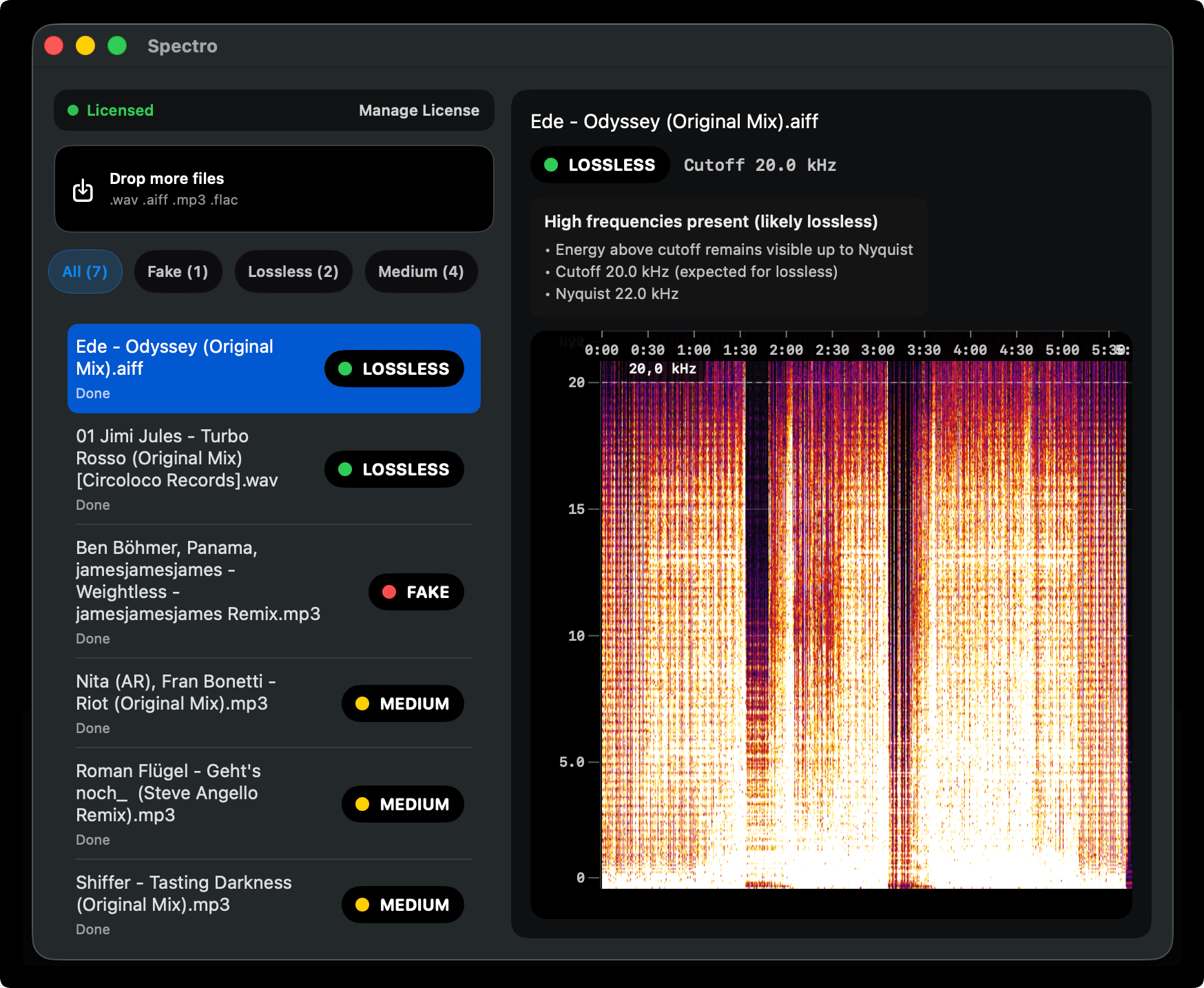
How Spectro implements this
Spectro applies the spectral frequency analysis method described in the ACM 2009 research to the practical problem of scanning music libraries at scale.
For each file, Spectro:
- Decodes the audio to PCM regardless of container format (WAV, AIFF, FLAC, or MP3)
- Runs FFT analysis across the full frequency spectrum
- Identifies the frequency cutoff pattern — its position, slope, and energy distribution
- Compares against known encoder fingerprints across bitrate classes
- Returns one of three verdicts: LOSSLESS, FAKE, or MEDIUM
The MEDIUM verdict directly reflects the 92.4% ambiguous zone documented in the ACM paper: high-bitrate CBR MP3 and high-quality VBR files that cannot be conclusively classified are explicitly flagged rather than forced into a binary outcome.
Detection is fully offline. No file leaves your Mac at any point in the process.
Frequently asked questions
What exactly is analyzed — the whole frequency spectrum? No. The diagnostic information is concentrated in the 16–20 kHz band. This is where different MP3 bitrates produce their most distinct fingerprints. Analysis of the full spectrum is done to find that band and characterize its cutoff pattern, but classification relies on the high-frequency region where encoder behavior diverges.
Does the detection method work for AAC-encoded audio inside FLAC? AAC cutoffs are less geometrically clean than MP3 cutoffs — they fade rather than drop as a hard wall. The frequency analysis still identifies the pattern, though with slightly less precision than for MP3. The AES 2015 filterbank method achieves 100% accuracy for AAC but requires significantly more computation per file.
Can detection be fooled by adding artificial high-frequency noise above the cutoff? In principle, yes — adding random noise above the cutoff could mask the fingerprint. In practice, this requires deliberate manipulation with knowledge of how detection tools work, and the resulting audio would sound noticeably different from an authentic recording. Stores and distribution platforms do not do this.
Why is 99% the number cited for Spectro's accuracy? The 99% figure corresponds to the transcoding detection accuracy from the ACM 2009 paper — identifying files that have been re-encoded from a lower bitrate to a higher one. This is the primary case for fake lossless: an MP3 re-wrapped as WAV or FLAC. The 97% figure is the broader bitrate classification rate; the 92.4% figure is specific to the 256 kbps vs. VBR-0 ambiguous zone, which Spectro marks as MEDIUM rather than issuing a definitive verdict.
Related posts
Try Spectro free
100 files free. No account needed. Buy for $39 when you're ready.
Download Spectro — $39